
Помогите, пожалуйста, исправить ошибку ValueError: Shape of passed values is (30471, 1), indices imply (30471, 4)
1234567891011121314151617181920212223242526272829303132333435363738
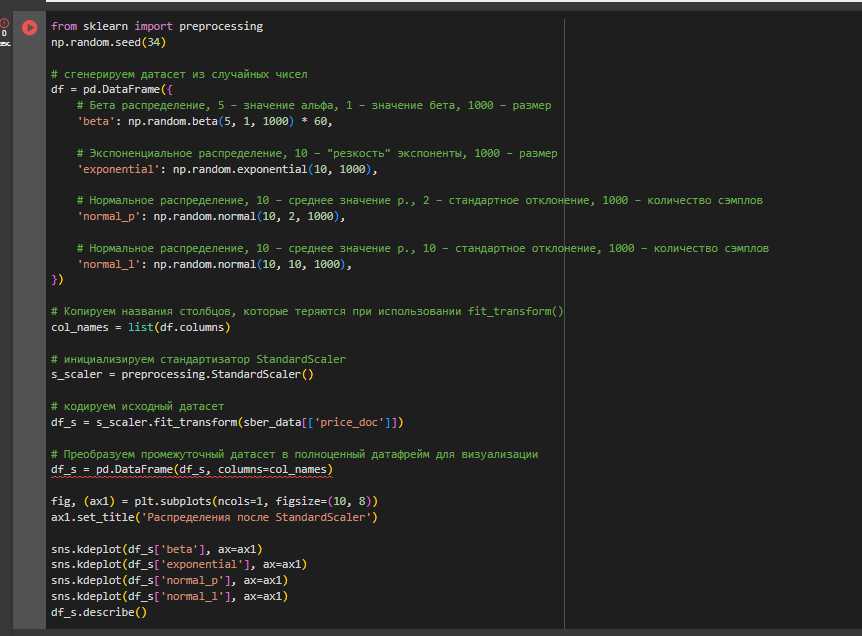
from sklearn import preprocessing
np.random.seed(34)
# сгенерируем датасет из случайных чисел
df = pd.DataFrame({
# Бета распределение, 5 – значение альфа, 1 – значение бета, 1000 – размер
'beta': np.random.beta(5, 1, 1000) * 60,
# Экспоненциальное распределение, 10 – "резкость" экспоненты, 1000 – размер
'exponential': np.random.exponential(10, 1000),
# Нормальное распределение, 10 – среднее значение р., 2 – стандартное отклонение, 1000 – количество сэмплов
'normal_p': np.random.normal(10, 2, 1000),
# Нормальное распределение, 10 – среднее значение р., 10 – стандартное отклонение, 1000 – количество сэмплов
'normal_l': np.random.normal(10, 10, 1000),
})
# Копируем названия столбцов, которые теряются при использовании fit_transform()
col_names = list(df.columns)
# инициализируем стандартизатор StandardScaler
s_scaler = preprocessing.StandardScaler()
# кодируем исходный датасет
df_s = s_scaler.fit_transform(sber_data[['price_doc']])
# Преобразуем промежуточный датасет в полноценный датафрейм для визуализации
df_s = pd.DataFrame(df_s, columns=col_names)
fig, (ax1) = plt.subplots(ncols=1, figsize=(10, 8))
ax1.set_title('Распределения после StandardScaler')
sns.kdeplot(df_s['beta'], ax=ax1)
sns.kdeplot(df_s['exponential'], ax=ax1)
sns.kdeplot(df_s['normal_p'], ax=ax1)
sns.kdeplot(df_s['normal_l'], ax=ax1)
df_s.describe() По дате
По рейтингу
Для исправления ошибки ValueError: Shape of passed values is (30471, 1), indices imply (30471, 4) вам нужно изменить строку кода, где вы используете StandardScaler. Вместо использования sber_data[['price_doc']], вам следует использовать df, который вы создали ранее.
Замените эту строку:
123456789
df_s = s_scaler.fit_transform(sber_data[['price_doc']])
```
На эту строку:
```python
df_s = s_scaler.fit_transform(df)
```
После этого ваш код должен успешно выполниться без ошибок. Надеюсь, это поможет! Если у вас возникнут еще вопросы, не стесняйтесь обращаться. 
Ошибка возникает из-за несоответствия между количеством столбцов в исходном датафрейме и количеством столбцов, которые вы пытаетесь использовать при создании нового датафрейма.
12345678910111213141516171819202122232425262728293031323334
from sklearn import preprocessing
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
np.random.seed(34)
# сгенерируем датасет из случайных чисел
df = pd.DataFrame({
'beta': np.random.beta(5, 1, 1000) * 60,
'exponential': np.random.exponential(10, 1000),
'normal_p': np.random.normal(10, 2, 1000),
'normal_l': np.random.normal(10, 10, 1000),
})
# инициализируем стандартизатор StandardScaler
s_scaler = preprocessing.StandardScaler()
# кодируем исходный датасет
df_s = s_scaler.fit_transform(df)
# Преобразуем промежуточный датасет в полноценный датафрейм для визуализации
df_s = pd.DataFrame(df_s, columns=df.columns)
fig, ax1 = plt.subplots(ncols=1, figsize=(10, 8))
ax1.set_title('Распределения после StandardScaler')
sns.kdeplot(data=df_s, ax=ax1)
plt.legend(df_s.columns)
print(df_s.describe())
plt.show()